Monitoring LlamaIndex applications with PostHog and Langfuse
In this cookbook, we show you how to build a RAG application with LlamaIndex, observe the steps with Langfuse and analyze the data in PostHog.
What is LlamaIndex?
LlamaIndex (GitHub) is a data framework designed to connect LLMs with external data sources. It helps structure, index, and query data effectively. This makes it easier for developers to build advanced LLM applications.
What is Langfuse?
Langfuse is an open-source LLM engineering platform. It includes features such as traces, evals, and prompt management to help you debug and improve your LLM app.
What is PostHog?
PostHog is a popular choice for product analytics. Combining Langfuse’s LLM analytics with PostHog’s product analytics makes it easy to:
- Analyze User Engagement: Determine how often users interact with specific LLM features and understand their overall activity patterns.
- Correlate Feedback with Behavior: See how user feedback captured in Langfuse correlates with user behavior in PostHog.
- Monitor LLM Performance: Track and analyze metrics such as model cost, latency, and user feedback to optimize LLM performance.
How to build a Simple RAG app with LlamaIndex and Mistral
In this example, we create a chat app that answers questions about how to care for hedgehogs. LlamaIndex vectorizes a hedgehog care guide using the Mistral 8x22B model. Then, all model generations are traced using Langfuse’s LLamaIndex integration.
Lastly, the PostHog integration enables you to view detailed analytics about your hedgehog app directly in PostHog.
Step 1: Set up LlamaIndex and Mistral
First, we set our Mistral API key as an environment variable. If you haven’t already, sign up for a Mistral acccount. Then subscribe to a free trial or billing plan, after which you’ll be able to generate an API key (💡 You can use any other model supported by LlamaIndex; we just use Mistral in this cookbook).
Then, we use LlamaIndex to initialize both a Mistral language model and an embedding model. We then set these models in the LlamaIndex Settings object:
%pip install llama-index llama-index-llms-mistralai llama-index-embeddings-mistralai nest_asyncio --upgrade# Set the Mistral API key
import os
os.environ["MISTRAL_API_KEY"] = "***Your-Mistral-API-Key***"
# Ensures that sync and async code can be used together without issues
import nest_asyncio
nest_asyncio.apply()
# Import and set up llama index
from llama_index.llms.mistralai import MistralAI
from llama_index.embeddings.mistralai import MistralAIEmbedding
from llama_index.core import Settings
# Define your LLM and embedding model
llm = MistralAI(model="open-mixtral-8x22b", temperature=0.1)
embed_model = MistralAIEmbedding(model_name="mistral-embed")
# Set the LLM and embedding model in the Settings object
Settings.llm = llm
Settings.embed_model = embed_modelStep 2: Initialize Langfuse
Next, we initialize the Langfuse client. Sign up for Langfuse if you haven’t already. Copy your API keys from your project settings and add them to your environment.
%pip install langfuseimport os
# Get keys for your project from the project settings page
# https://cloud.langfuse.com
os.environ["LANGFUSE_PUBLIC_KEY"] = ""
os.environ["LANGFUSE_SECRET_KEY"] = ""
os.environ["LANGFUSE_HOST"] = "https://cloud.langfuse.com" # 🇪🇺 EU region
# os.environ["LANGFUSE_HOST"] = "https://us.cloud.langfuse.com" # 🇺🇸 US region
# Your openai key
os.environ["OPENAI_API_KEY"] = ""from langfuse import Langfuse
langfuse = Langfuse()Lastly, we register Langfuse’s LlamaIndexCallbackHandler in the LlamaIndex Settings.callback_manager at the root of the app.
Find out more about the Langfuse’s LlamaIndex integration here.
from llama_index.core import Settings
from llama_index.core.callbacks import CallbackManager
from langfuse.llama_index import LlamaIndexCallbackHandler
langfuse_callback_handler = LlamaIndexCallbackHandler()
Settings.callback_manager = CallbackManager([langfuse_callback_handler])Step 3: Download data
We download the file we want to use for RAG. In this example, we use a hedgehog care guide pdf file to enable the language model to answer questions about caring for hedgehogs 🦔.
!wget 'https://www.pro-igel.de/downloads/merkblaetter_engl/wildtier_engl.pdf' -O './hedgehog.pdf'--2024-09-20 13:16:39-- https://www.pro-igel.de/downloads/merkblaetter_engl/wildtier_engl.pdf
Resolving www.pro-igel.de (www.pro-igel.de)... 152.53.23.200
Connecting to www.pro-igel.de (www.pro-igel.de)|152.53.23.200|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1160174 (1.1M) [application/pdf]
Saving to: ‘./hedgehog.pdf’
./hedgehog.pdf 100%[===================>] 1.11M 2.03MB/s in 0.5s
2024-09-20 13:16:40 (2.03 MB/s) - ‘./hedgehog.pdf’ saved [1160174/1160174]Next, we load the pdf using the LlamaIndex SimpleDirectoryReader.
from llama_index.core import SimpleDirectoryReader
hedgehog_docs = SimpleDirectoryReader(input_files=["./hedgehog.pdf"]).load_data()Step 4: Build RAG on the hedgehog doc
Next, we create vector embeddings of the hedgehog document using VectorStoreIndex and then convert it into a queryable engine to retrieve information based on queries.
from llama_index.core import VectorStoreIndex
hedgehog_index = VectorStoreIndex.from_documents(hedgehog_docs)
hedgehog_query_engine = hedgehog_index.as_query_engine(similarity_top_k=5)Finally, to put everything together, we query the engine and print a response:
response = hedgehog_query_engine.query("Which hedgehogs require help?")
print(response)Hedgehogs that require help are those that are sick, injured, and helpless, such as orphaned hoglets. These hedgehogs in need may be temporarily taken into human care and must be released into the wild as soon as they can survive there independently.All steps of the LLM chain are now tracked in Langfuse.
Example trace in Langfuse: https://cloud.langfuse.com/project/cloramnkj0002jz088vzn1ja4/traces/367db23d-5b03-446b-bc73-36e289596c00
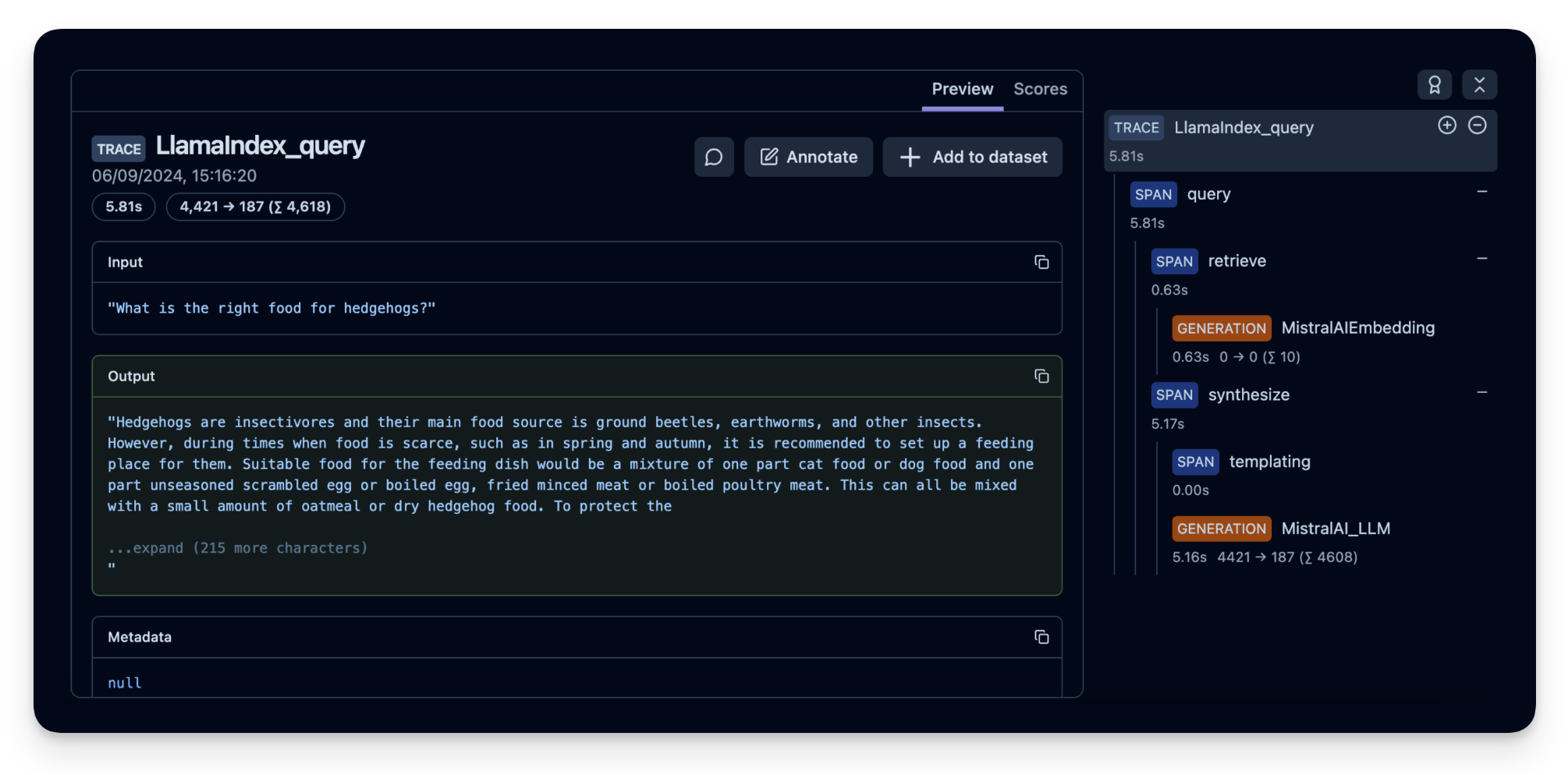
Step 5: (Optional) Implement user feedback to see how your application is performing
To monitor the quality of your hedgehog chat application, you can use Langfuse Scores to store user feedback (e.g. thumps up/down or comments). These scores can then be analysed in PostHog.
Scores are used to evaluate single observations or entire traces. You can create them via the annotation workflow in the Langfuse UI, run model-based evaluation or ingest via the SDK as we do it in this example.
To get the context of the current observation, we use the observe() decorator and apply it to the hedgehog_helper() function.
from langfuse.decorators import langfuse_context, observe
# Langfuse observe() decorator to automatically create a trace for the top-level function and spans for any nested functions.
@observe()
def hedgehog_helper(user_message):
response = hedgehog_query_engine.query(user_message)
trace_id = langfuse_context.get_current_trace_id()
print(response)
return trace_id
trace_id = hedgehog_helper("Can I keep the hedgehog as a pet?")
# Score the trace, e.g. to add user feedback using the trace_id
langfuse.score(
trace_id = trace_id,
name="user-explicit-feedback",
value=0.9,
data_type="NUMERIC", # optional, inferred if not provided
comment="Good to know!", # optional
)Based on the provided context, it is not recommended to keep wild hedgehogs as pets. The Federal Nature Conservation Act protects hedgehogs as a native mammal species, making it illegal to chase, catch, injure, kill, or take their nesting and refuge places. Exceptions apply only to sick, injured, and helpless hedgehogs, which may be temporarily taken into human care and released into the wild as soon as they can survive independently. It is important to respect the natural habitats and behaviors of wild animals, including hedgehogs.
<langfuse.client.StatefulClient at 0x7c7cd656e2f0>Step 6: See your data in PostHog
Finally, we connect PostHog to our Langfuse account. Below is a summary of the steps to take (or see the docs for full details):
- Sign up for your free PostHog account if you haven’t already
- Copy both your project API key and host from your project settings.
- In your Langfuse dashboard, click on Settings and scroll down to the Integrations section to find the PostHog integration.
- Click Configure and paste in your PostHog host and project API key (you can find these in your PostHog project settings).
- Click Enabled and then Save.
Langfuse will then begin exporting your data to PostHog once a day.
Using the Langfuse dashboard template:
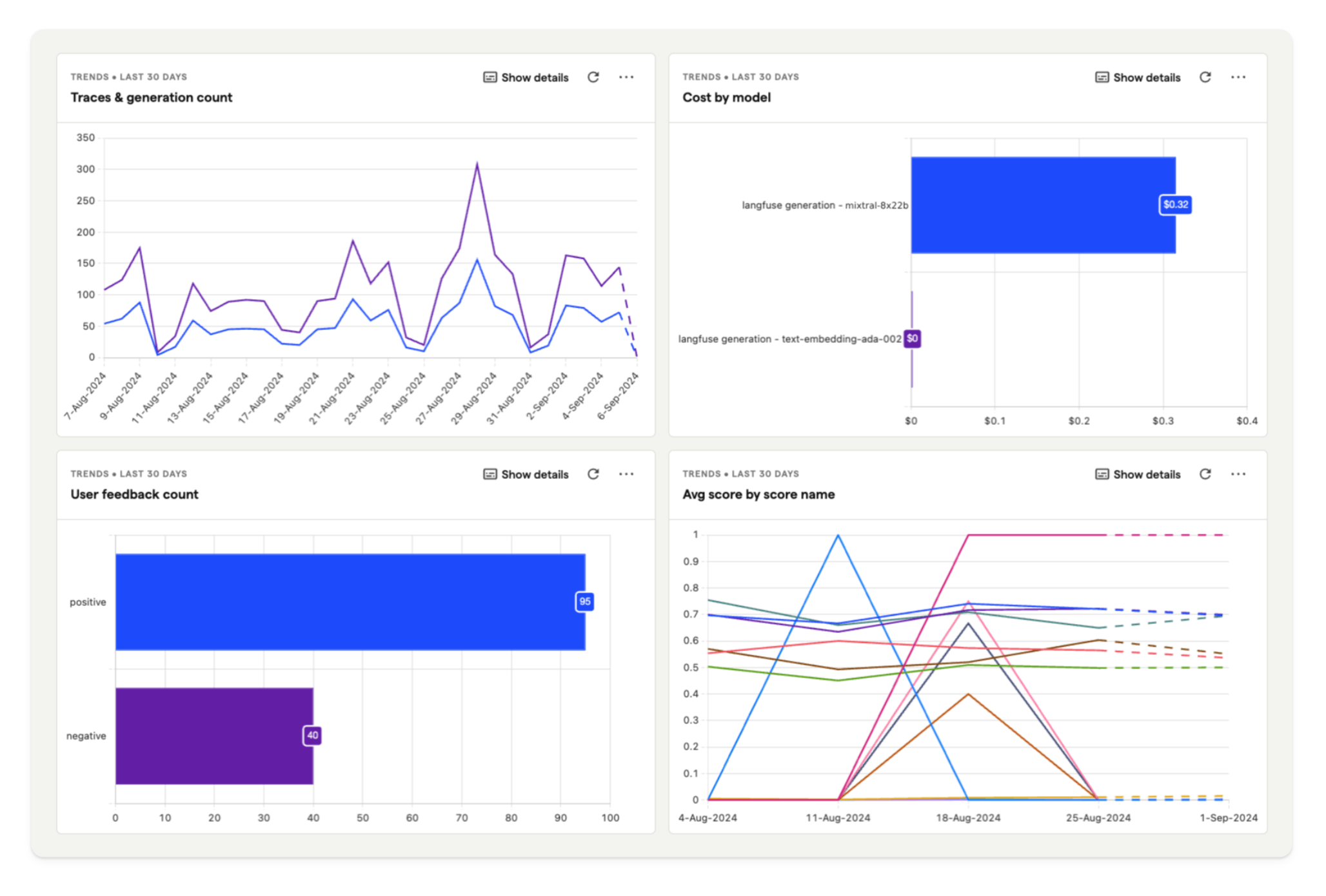
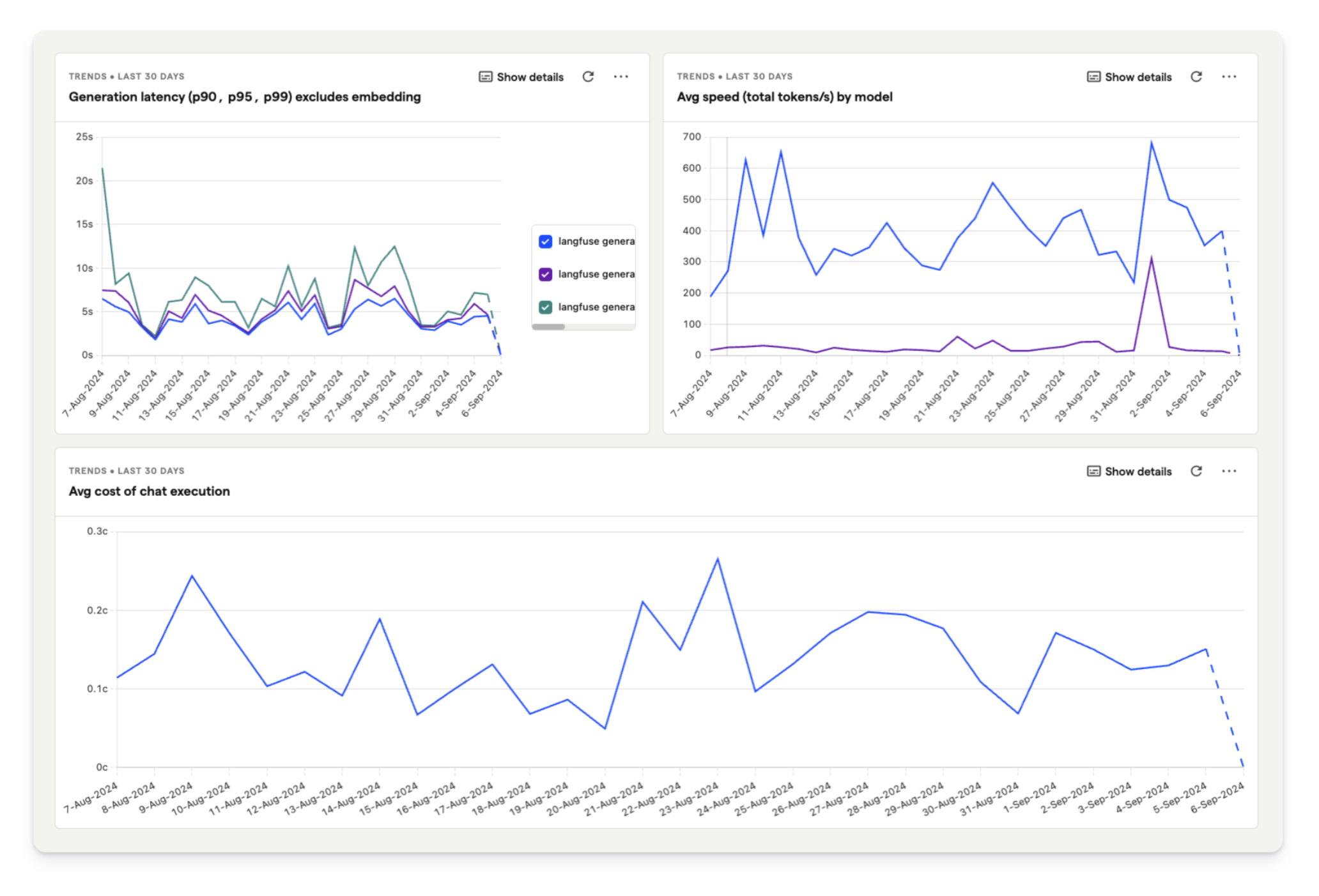
Once you’ve installed the integration, dashboard templates help you quickly set up relevant insights.
For our hedgehog chat application, we are using the template dashboard shown below. This enables you to analyze model cost, user feedback, and latency in PostHog.
To create your own dashboard from a template:
- Go to the dashboard tab in PostHog.
- Click the New dashboard button in the top right.
- Select LLM metrics – Langfuse from the list of templates.
Feedback
If you have any feedback or requests, please create a GitHub Issue or share your idea with the community on Discord.